Bất đồng bộ trong Python - Coroutine | Phần 1
Thứ sáu, ngày 19 tháng 3 năm 2021Bất đồng bộ là một khái niệm rất hay gặp trong các ngôn ngữ lập trình như Javascript, Kotlin hay Python. Đặc biệt, các lập trình viên làm việc nhiều với networking như các web developer thường xuyên phải làm việc với khái niệm này. Trong bài viết này, mình sẽ giải thích một trong các thành phần cấu tạo nên hệ sinh thái async programming trong Python và tất nhiên, nó cũng mang tư tưởng này lên một số ngôn ngữ khác.
Mục tiêu
- Tìm hiểu và so sánh các mô hình lập trình cho vấn đề xử lí bất đồng bộ
- Bất đồng bộ và một vài cách tiếp cận
- Coroutine là gì? Chúng làm việc như thế nào? So sánh các đơn vị xử lí
- Coroutine trong ứng dụng thực tế
Bất đồng bộ là gì?
Theo Wikipedia
Asynchrony, in computer programming, refers to the occurrence of events independent of the main program flow and ways to deal with such events. These may be "outside" events such as the arrival of signals, or actions instigated by a program that takes place concurrently with program execution, without the program blocking to wait for results. Asynchronous input/output is an example of the latter cause of asynchrony, and lets programs issue commands to storage or network devices that service these requests while the processor continues executing the program. Doing so provides a degree of parallelism
Hình ảnh bên dưới cho chúng ta thấy một vài giải pháp cho các vấn đề về bất đồng bộ
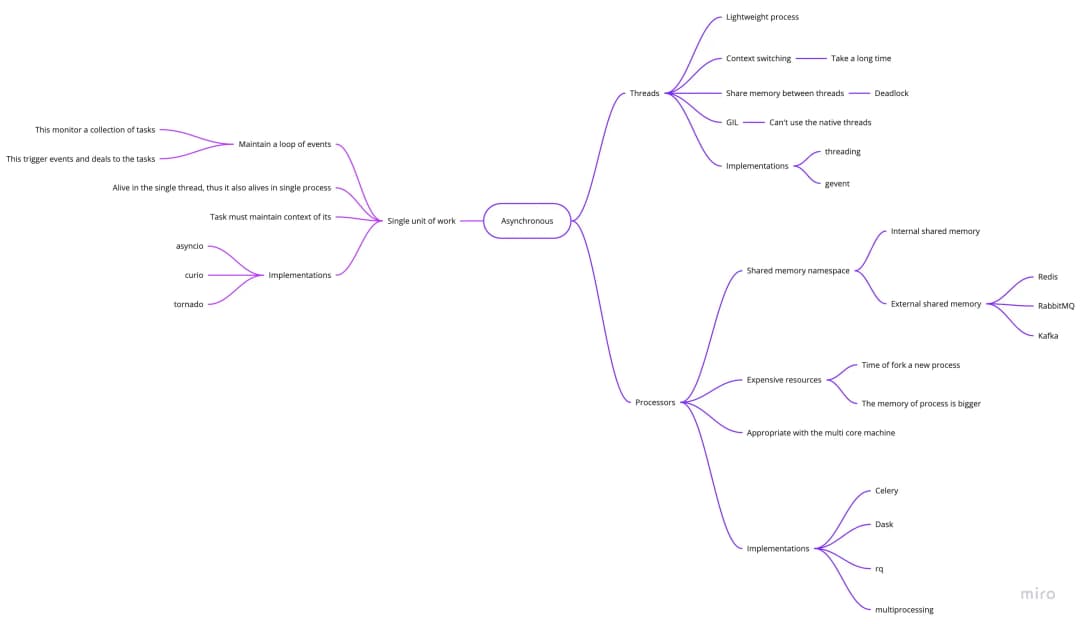
Hệ sinh thái của lập trình bất đồng bộ
Lưu ý, các thread trong Python là các native thread, nhưng do một vài policy (cụ thể là trong bản cpython), GIL (Global Interpreter Lock) sẽ không cho phép chúng chạy 2 thread đồng thời. Do đó, các Python thread không thực xử xử lí song song và thật sự mình không thích sử dụng chúng do:
- Tốn tài nguyên duy trì
- Fork một thread mới là cực kì tốn thời gian
Chúng ta có thể thấy rằng, các thread và process đều sở hữu một không gian bộ nhớ của riêng nó, do đó, chúng có thể thực hiện các công việc độc lập với main thread hay main process
Trái lại, event loop duy trì các task, các task này chia sẻ bộ nhớ chung và chúng ta phải trả lời câu hỏi: Làm thế nào chúng ta có thể tổ chức không gian bộ nhớ cho các task độc lập?
Khi nào chúng ta sử dụng event loop, thread hay process?
Trong khoa học máy tính, chúng ta có thể phân task thành 2 loại:
- Ràng buộc bởi CPU
Trong khoa học máy tính, máy tính bị ràng buộc bởi CPU (hoặc giới hạn máy tính) khi thời gian để nó hoàn thành một tác vụ chủ yếu được xác định bởi tốc độ của bộ xử lý trung tâm: mức sử dụng bộ xử lý cao, có thể ở mức sử dụng 100% trong nhiều giây hoặc phút. Các ngắt do thiết bị ngoại vi tạo ra có thể được xử lý chậm hoặc bị trì hoãn vô thời hạn.
- Ràng buộc bởi I/
Ràng buộc I/O đề cập đến điều kiện trong đó thời gian cần thiết để hoàn thành một phép tính chủ yếu được xác định bằng khoảng thời gian chờ các hoạt động vào/ra được hoàn thành. Điều này ngược lại với một tác vụ bị ràng buộc bởi CPU. Trường hợp này phát sinh khi tốc độ dữ liệu được lấy chậm hơn tốc độ nó được sử dụng hoặc nói cách khác, dành nhiều thời gian hơn để lấy dữ liệu hơn là xử lý nó
Ví dụ:
-
sử dụng event loop cho các task ràng buộc bởi CPU
Jason hỏi David rằng 'Bạn làm gì ngày hôm nay?' và David trả lời rằng những công việc của anh ấy đang chờ để test và anh ấy không có task nào cả do đó anh ấy sẽ quay về nhà và 😴.
Không, nó không phải là một giải pháp tối ưu. Thay vào đó, David nên thực hiện các task khác cho đến khi Ms.Tee nói rằng 'Hey David, các task của bạn chưa đạt, sửa lại nó đi' 😥.
Chính xác đây là cách làm việc của event loop cho các task ràng buộc bởi I/O
-
sử dụng đa tiến trình (hoặc các native thread) cho các task ràng buộc bởi I/O
Nhóm bạn có 5 thành viên và 5 task nhưng chỉ có David làm tất cả các task đó. Bởi vì mỗi task phải được commit vào cuối mỗi ngày nên David làm 1 task trong 1 giờ và chuyển qua task khác. Do đó, cuối tuần, anh ấy kiệt sức và ốm 😷.
Không, chúng ta có tận 5 thành viên, tại sao chúng ta lại đẩy hết công việc cho David? Jason có thể phân chia các task cho các thành viên khác và cuối mỗi ngày, các task vẫn được commit và David vẫn ổn cơ mà.
Đây là cách mà xử lí đa tiến trình thực hiện.
Qua ví ví dụ trên, ta thây rằng event loop chỉ thực sự hữu dụng trong vấn đề liên quan đến IO bound. Chúng được sử dụng trong các event system và những hệ thống tương tự. Chúng có thể là giải pháp tốt nhất cho các vấn để liên quan đến IO bound.
Các vấn đề trong mô hình event loop
Chúng ta đã biết rằng chúng ta có một context của một hàm bất kì. Context này bao gồm các biến và chúng được giải phóng sau khi hàm kết thúc (giải phóng ra khỏi stack).
Trong I/O-bound task, chúng ta sẽ có một vài lệnh lấy dữ liệu (IO operation) mà tại đó chúng ta cần tối ưu (như ví dụ về David, anh ta có thể tạm ngưng các task bị pending bởi test và chuyển qua làm task khác rồi quay lại làm các task của anh ta).
Như vậy các ngắt là một vấn đề, làm sao chúng ta có thể tạo ra các ngắt trong hàm mà vẫn giữ được context của hàm để có thể thực thi tiếp?
Tại các ngắt đó, hàm đang thực thi(callee) cần trao lại quyền điều khiển chương trình (program control) cho nơi đã gọi hàm đó (caller), ở đây thực chất là event loop và chúng ta cũng cần bắt đầu tại điểm ngắt này khi caller trao quyền điều khiển cho callee khi nó được thực thi tiếp.
Giải pháp ở đây là sử dụng coroutine
Coroutine là gì?
Donald Knuth nói rằng:
Subroutines là một trường hợp cơ bản của coroutine
Đúng vậy, tổng quát hoá, các hàm bình thường chúng ta hay sử dụng (hàm bị giải phóng context sau khi thoát khỏi hàm) là trường hợp đặc biệt của coroutine - nơi đó context có thể được giữ lại khi nó được tạm dùng.
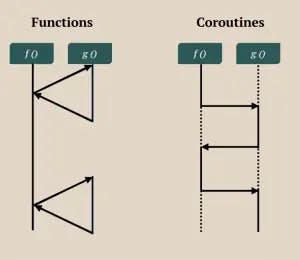
Subroutine vs Coroutine
Tại sao coroutine lại hữu dụng cho event system?
- là non-preemptive scheduling
- có thể tạm dừng và tiếp tục tại bất kì đâu do đó, nếu dữ liệu là stream, chúng có thể tiếp kiệm bộ nhớ
- có thể duy trì trạng thái
- với ràng buộc về I/O, coroutine tối ưu bộ nhớ và CPU
- chúng nhỏ gọn
Đơn vị làm việc
| Process | Native thread | Green thread | Goroutine | Coroutine | |
|---|---|---|---|---|---|
| Bộ nhớ | ≤ 8Mb | ≤ Nx2Mb | ≥ 64Kb | ≥ 8Kb | ≥ 0Mb |
| Quản lí bởi OS | Yes | Yes | No | No | No |
| Không gian địa chỉ riêng | Yes | No | No | No | No |
| Pre-emptive scheduling | Yes | Yes | Yes | No | No |
| Khả năng song song | Yes | Yes | No | Yes | No |
Câu hỏi là: Vậy coroutine làm việc như thế nào?
Làm thế nào để cài đặt một coroutine?
#include <stdio.h>
int coroutine() {
static int i = 0, s = 0;
switch (s) {
case 0:
for (i = 0;; ++i) {
if (!s) s = 1;
return i;
case 1:;
}
}
}
int main(int argc, char** argv) {
printf("%d\n", coroutine()); // ?
printf("%d\n", coroutine()); // ?
printf("%d\n", coroutine()); // ?
return 0;
}
Về cơ bản, nó cố gắng lưu lại trạng thái của hàm trong biến i và biến s đóng vai trò như là ngắt. Trước khi tạm dừng hàm(suspend), biến s được set là điểm bắt đầu khi nó được khôi phục(resume).
Trong đoạn code này, điểm chính là biến s và cách mà code có thể resume và suspend coroutine bằng cách dùng switch case
Và ở bên dưới, nó được chuyển sang Python code từ code C ở trên
def coroutine():
i = 0
while 1:
yield i
i += 1
co = coroutine()
next(co)
next(co)
next(co)
Bạn có thể chuyển Python code này sang C?
def fib():
a, b = 0, 1
while True:
yield a
a, b = a + b, a
co = fib()
for _ in range(10):
print(next(co), end=' ')
Sau đó, bạn nên thấy kết quản như thế này
0 1 1 2 3 5 8 13 21 34
Mình có thể build bất kì một coroutine nào trong C. Bạn có thể làm được điều đó không?
#include <stdio.h>
int fib() {
static int i, __resume__ = 0;
static a = 0, b = 1, c;
switch (__resume__) {
case 0:
for (i = 0;; ++i) {
if (!__resume__) __resume__ = 1;
c = a + b;
b = a;
a = c;
return a;
case 1:;
}
}
}
int main() {
for (int i = 0; i < 10; ++i) {
printf("%d ", fib());
}
return 0;
}
def say():
yield "C"
yield "Java"
yield "Python"
co = say()
print(next(co))
print(next(co))
print(next(co))
print(next(co))
Kết quả có thể thấy
C
Java
Python
---------------------------------------------------------------------------
StopIteration Traceback (most recent call last)
<ipython-input-1-913b1d7d4200> in <module>
8 print(next(co))
9 print(next(co))
---> 10 print(next(co))
StopIteration:
#include <stdio.h>
char* say() {
static int __resume__ = 0;
switch (__resume__) {
case 0:
__resume__ = 1;
return "C";
case 1:
__resume__ = 2;
return "Java";
case 2:
__resume__ = 3;
return "Python";
default:
return NULL; // GeneratorExit
}
}
int main() {
printf("%s\n", say());
printf("%s\n", say());
printf("%s\n", say());
printf("%s\n", say());
return 0;
}
Chúng ta có thể thấy rằng, coroutine cần một không gian bộ nhớ tĩnh để lưu lại trạng thái khi nó suspend và khôi phục lại mà không bị mất context. Trong C, không gian tĩnh là các biến static, chúng duy trì bởi OS khi một hàm thoát. Trong Python, context của hàm được lưu trữ trong các stack frame.
Hãy nghĩ về các coroutine như là các đoạn của một chương trình, không có bộ nhớ riêng, không thực thi song song và cực kì an toàn.
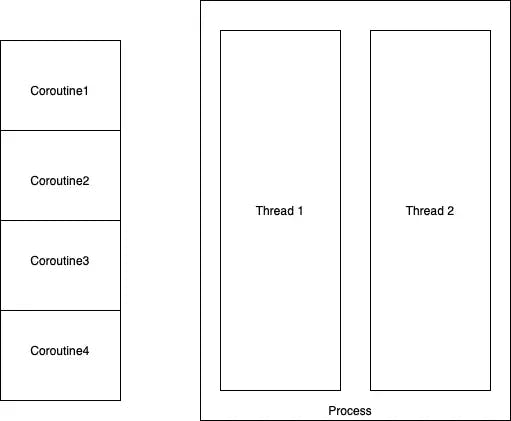
Coroutine vs Thread
Coroutine giảm các lỗi do xử lí đa tiến trình (đa luồng) gây ra và mình nghĩ nó là giải pháp tốt nhất cho các task liên quan đến networking bởi nó chỉ tồn tại trong 1 tiến trình.
Trong Python, chúng ta có thể định nghĩa coroutine bằng việc sử dụng lệnh yield trong định nghĩa hàm. Khi chúng ta gọi hàm, chúng trả về một coroutine thay vì kết quả cuối cùng.
def coro_fn():
val = yield 'Starting' # started coroutine and suspend, return control to caller
print('Consume', val)
yield 'Hello World' # produce data
co = coro_fn() # create a new coroutine object
print(co.send(None)) # start coroutine
print(co.send('data')) # resume coroutine, pass control into coroutine
co.close() # close coroutine
Sau đó, kết quả có thể thấy
Starting
Consume data
Hello World
Generator là một trường hợp đặc biệt của coroutine, chúng chỉ có thể sinh(produce) dữ liệu mà không thể tiêu thụ(consuming) dữ liệu.
def g1():
for i in range(10):
yield i
def g2():
for i in range(10, 20):
yield i
def g():
for i in g1():
yield i
for i in g2():
yield i
list(g())
Và đây là kết quả
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19]
Chúng ta có thể refactor đoạn code với yield from
def g():
yield from g1()
yield from g2()
list(g())
Build binary tree with yield from
Build cây nhị phân với yeild from
class Node:
def __init__(self, value=None, left_nodes=None, right_node=None):
self.left_nodes = left_nodes or []
self.right_nodes = right_node or []
self.value = value
def visit(self):
for node in self.left_nodes:
yield from node.visit()
yield self.value
for node in self.right_nodes:
yield from node.visit()
root = Node(
0,
[Node(1, [Node(7), Node(8)]), Node(2, None, [Node(9), Node(10)]), Node(3)],
[Node(4), Node(5), Node(6)]
)
for value in root.visit():
print(value, end=' ')
7 8 1 2 9 10 3 0 4 5 6
Ứng dụng của coroutine
1. Máy chủ TCP bất đồng bộ
Trong trường hợp này, một máy chủ TCP là một event system
-
event source: socket lắng nghe và các socket kết nối
-
về cơ bản, chúng ta có hai dạng sự kiện: EVENT_READ, EVENT_WRITE
-
và các task là các coroutine, mỗi task sẽ xử lí 1 sự kiện của 1 kết nối tại 1 thời điểm
-
Chúng ta cũng có một event loop, nó là một bộ I/O multiplexing cho file descriptor
import logging
from sys import stdout
from socket import socket, SOCK_STREAM, AF_INET
from selectors import DefaultSelector, EVENT_READ, EVENT_WRITE
logging.basicConfig(stream=stdout, level=logging.DEBUG)
class Server:
def __init__(self, host, port, buf_size=64):
self.addr = (host, port)
self.poll = DefaultSelector()
self.m = {}
self.buf_size = buf_size
def handle_read(self, sock): # tạo ra một context độc lâp cho mỗi kết nối
buffer_size = self.buf_size
handle_write = self.handle_write
def _can_read():
chunks = []
while 1:
chunk = sock.recv(buffer_size)
if chunk.endswith(b'\n\n'):
chunks.append(chunk[:-2])
break
else:
chunks.append(chunk)
yield
handle_write(sock, b''.join(chunks))
handler = _can_read()
self.m[sock] = handler
self.poll.register(sock, EVENT_READ, handler)
def handle_write(self, sock, data): # tạo ra một context độc lâp cho mỗi kết nối
poll = self.poll
m = self.m
buffer_size = self.buf_size
def _can_write():
nonlocal data, sock
start_, end_ = 0, 0
data = b'Hello ' + data
len_data = len(data)
while 1:
end_ = min(start_ + buffer_size, len_data)
if start_ >= end_:
break
sock.send(data[start_:end_])
start_ += buffer_size
yield # trả quyền điều khiển cho event loop để chờ đến khi socket sẵn sàng ghi
# đóng và giải phóng các socket
poll.unregister(sock)
del m[sock]
sock.close()
del sock
handler = _can_write()
m[sock] = handler
poll.modify(sock, EVENT_WRITE, handler)
def handle_accept(self, sock):
while 1:
s, addr = sock.accept()
logging.debug(f'Accept the connection from {addr}')
self.handle_read(s)
yield
def mainloop(self):
try:
sock = socket(AF_INET, SOCK_STREAM)
sock.bind(self.addr)
sock.setblocking(0)
sock.listen(1024)
self.m[sock] = self.handle_accept(sock)
self.poll.register(sock, EVENT_READ, self.m[sock])
logging.info(f'Server is running at {self.addr}')
while 1:
events = self.poll.select()
for event, _ in events:
try:
cb = event.data
next(cb)
except StopIteration:
pass
except Exception as e:
sock.close()
self.poll.close()
raise e
Bạn có thể chạy nó
server = Server('127.0.0.1', 5000)
server.mainloop()
Trình lập lịch và task trong các thư viện thực tế: Kernal curio
2. Streaming system
Chúng ta có thể sử dụng coroutine để build một hệ thống xử lí dữ liệu. Về cơ bản, hệ thống tách biệt các khối logic nhỏ. Chúng được đặt vào các coroutine với context riêng. Bạn có thể thấy chúng trong hình bên dưới.
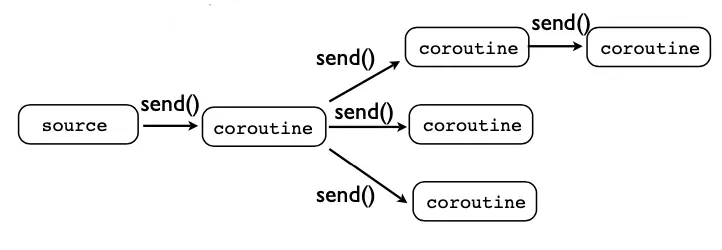
Mô hình xử lí dữ liệu
Event source có thể là Redis pub/sub, Kafka, RabbitMQ hoặc các tương tác người dùng,...
Chúng ta có thể mô tả bất kì loại hệ thống nào nếu chúng ta tạo ta có khối logic cụ thể: khối lọc dữ liệu, khối điều kiện, bộ chọn, khối broadcast...
Ví dụ: build một bộ phân tích địa chỉ IP truy cập của một webserver
Đầu tiên, bạn cần một file dữ liệu log
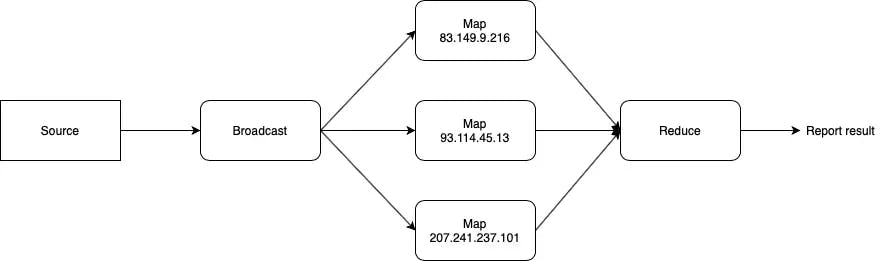
Thống kê IP
def coroutine(f):
def decorator(*args, **kwargs):
co = f(*args, **kwargs)
co.send(None) # start coroutine before it's used
return co
return decorator
@coroutine
def broadcast(targets):
try:
while 1:
data = yield
for target in targets:
target.send(data)
except GeneratorExit:
for target in targets:
target.close()
@coroutine
def map_(ip, next_):
try:
while 1:
data = yield
if data.startswith(ip):
next_.send(ip)
except GeneratorExit:
next_.close()
@coroutine
def reduce_(on_done):
m = {}
try:
while 1:
data = yield
if data not in m:
m[data] = 1
else:
m[data] += 1
except GeneratorExit:
on_done(m)
Sau đó chạy
result = {}
def on_done(r):
global result
result = r
reducer = reduce_(on_done)
flow = broadcast([
map_('83.149.9.216', reducer),
map_('93.114.45.13', reducer),
map_('207.241.237.101', reducer),
])
# this is the source data
# We have 10000 lines in this log
%time
with open('assets/files/access.log', 'r') as fp:
for line in fp.readlines():
flow.send(line)
flow.close()
print(result)
Kết quả có thể thấy
CPU times: user 2 µs, sys: 1e+03 ns, total: 3 µs
Wall time: 5.25 µs
{'83.149.9.216': 23, '93.114.45.13': 6, '207.241.237.101': 17}
Cải thiện
Chúng ta có thể bọc các thread trong một couroutine, tại sao không?
Đơn giản, chúng ta sử dụng các thread thay cho các máy
OK, hãy thiết kế tại cái sơ đồ nào
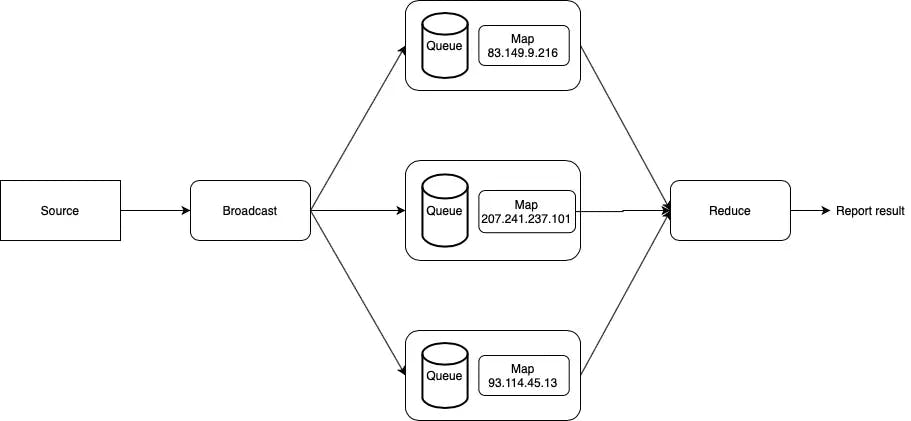
Kết hợp coroutine và thread
Trong sơ đồ trên, mình chuyển các logic vào trong các thread và sử dụng hàng đợi như là kênh giao tiếp với các thread.
Không chỉ vậy, hàng đơi còn đóng vai trò như là các buffer nếu tốc độ đầu vào lớn hơn tốc độ đầu ra của đơn vị xử lí đó.
from threading import Thread
from queue import Queue
def coroutine(f):
def decorator(*args, **kwargs):
co = f(*args, **kwargs)
co.send(None)
return co
return decorator
@coroutine
def broadcast_threaded(targets):
queue = Queue()
def _run_target():
nonlocal queue, targets
while 1:
data = queue.get()
if data is GeneratorExit:
for target in targets:
target.close()
return
else:
for target in targets:
target.send(data)
Thread(target=_run_target).start()
try:
while 1:
data = yield
queue.put(data)
except GeneratorExit:
queue.put(GeneratorExit)
@coroutine
def map_threaded(ip, next_):
queue = Queue()
def _run_target():
nonlocal ip, queue
while 1:
data = queue.get()
if data is GeneratorExit:
next_.close()
return
else:
if data.startswith(ip):
while next_.gi_running:
pass
next_.send(ip)
queue.task_done()
Thread(target=_run_target).start()
try:
while 1:
data = yield
queue.put(data)
except GeneratorExit:
queue.put(GeneratorExit)
@coroutine
def reduce_threaded(on_done):
m = {}
queue = Queue()
def _run_target():
nonlocal queue, m, on_done
while 1:
data = queue.get()
if data is GeneratorExit:
on_done(m)
return
else:
if data not in m:
m[data] = 1
else:
m[data] += 1
Thread(target=_run_target).start()
try:
while 1:
data = yield
queue.put(data)
except GeneratorExit:
queue.put(GeneratorExit)
Và chạy nó như sau
result = {}
def on_done(r):
global result
result = r
reducer = reduce_threaded(on_done)
flow = broadcast_threaded([
map_threaded('83.149.9.216', reducer),
map_threaded('93.114.45.13', reducer),
map_threaded('207.241.237.101', reducer),
])
# this is the source data
# We have 10000 lines in this log
%time
with open('assets/files/access.log', 'r') as fp:
for line in fp.readlines():
flow.send(line)
flow.close()
print(result) # result?
Then
CPU times: user 2 µs, sys: 0 ns, total: 2 µs
Wall time: 5.72 µs
{}
Oh, Tại sao kết quả lại rỗng?
Mình cho các bạn gợi ý, hay thêm câu lệnh sleep trước câu lệnh print xem sao :smile:
Lưu ý
-
Khi chúng ta sử dụng coroutine, chúng ta nên xem xét coroutine có thể bị overload hay không. Nghĩa là, tại một thời điểm, coroutine đó có thể vừa bị đẩy dữ liệu vào, vừa đang xử lí dữ liệu bên trong nó hay không? Nó là một trường hợp khá nguy hiểm, khiến cho chương trình có thể bị crash.
-
Tránh các thiết kế DAG
-
Chỉ gọi
send()trong luồng đồng bộ, ý mình là chỉ gọisend()trong một single thread.
3. Bộ lập lịch cho OS
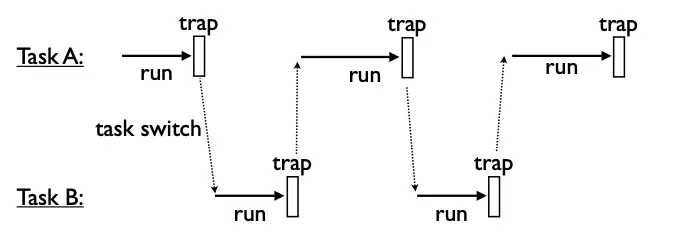
Operation system scheduler
Khi một câu lệnh trong một task hit trap, task sẽ trả lại quyền điều khiển cho OS và OS thực thi lệnh hoặc chuyển quyền điều khiển cho task khác trong hàng đợi.
Nó là một non-preemptive scheduler, qua ví dụ dưới đây, các bạn có thể hiểu mối liên hệ giữa. trap trong OS và yield trong Python.
from queue import Queue
class SystemCall:
__slots__ = ('sched', 'target')
def handle(self):
pass
class Task:
__slots__ = ('id', 'target', 'sendval')
_id = 0
def __init__(self, target):
Task._id += 1
self.id = Task._id
self.target = target
self.sendval = None
def run(self):
return self.target.send(self.sendval)
class Scheduler:
__slots__ = ('taskmap', 'ready')
def __init__(self):
self.taskmap = {}
self.ready = Queue()
def new(self, target):
task = Task(target)
self.taskmap[task.id] = task
self.schedule(task)
return task.id
def mainloop(self):
while self.taskmap:
task = self.ready.get()
try:
result = task.run()
if isinstance(result, SystemCall):
result.task = task
result.sched = self
result.handle()
continue
except StopIteration:
self.exit(task)
else:
self.schedule(task)
def schedule(self, task):
self.ready.put(task)
def exit(self, task):
print('Task %d terminated' % task.id)
del self.taskmap[task.id]
class GetTid(SystemCall):
def handle(self):
self.task.sendval = self.task.id
self.sched.schedule(self.task)
class NewTask(SystemCall):
def __init__(self, target):
self.target = target
def handle(self):
tid = self.sched.new(self.target)
self.task.sendval = tid
self.sched.schedule(self.task)
class KillTask(SystemCall):
def __init__(self, tid):
self.tid = tid
def handle(self):
task = self.sched.taskmap.get(self.tid, None)
if task:
task.target.close()
self.task.sendval = True
else:
self.task.sendval = False
self.sched.schedule(self.task)
OK, khởi động OS nào
def foo():
tid = yield GetTid()
print(f'I\'m foo and I am living in {tid} process')
for i in range(5):
print(f"Foo {tid} is in {i} step")
yield
def bar():
tid = yield GetTid()
print(f"I'm bar and I'm living in {tid} process")
yield NewTask(foo())
for i in range(3):
print(f"Bar {tid} is in {i} step")
yield
yield KillTask(1)
if __name__ == '__main':
sched = Scheduler()
sched.new(foo())
sched.new(bar())
sched.mainloop()
Và bạn có thể thấy
I'm foo and I am living in 1 process
Foo 1 is in 0 step
I'm bar and I'm living in 2 process
Foo 1 is in 1 step
Bar 2 is in 0 step
Foo 1 is in 2 step
I'm foo and I am living in 3 process
Foo 3 is in 0 step
Bar 2 is in 1 step
Foo 1 is in 3 step
Foo 3 is in 1 step
Bar 2 is in 2 step
Foo 1 is in 4 step
Foo 3 is in 2 step
Task 1 terminated
Foo 3 is in 3 step
Task 2 terminated
Foo 3 is in 4 step
Task 3 terminated
Thật kì diệu.
Hẹn gặp lại các bạn ở các bài viết sau.