Parsing và phân tích cú pháp
Thứ sáu, ngày 26 tháng 11 năm 2021Bạn có bao giờ thắc mắc rằng tại sao các trình biên dịch như C, Java, Rust lại có thể hiểu được những file source code hay tại sao một loại cú pháp nửa JS nửa HTML lại có thể chạy được trên các trình duyệt không? Bạn có bao giờ tự hỏi làm thế nào mà JS lại có nhiều biến thể như vậy và các công cụ như Typescript hay Babel lại có thể làm cho những đoạn code React, Typescript lại có thể chạy được trên trình duyệt.
Trong thế giới lập trình có rất nhiều ngôn ngữ lập trình và bên cạnh đó cũng tồn tại những công cụ dùng để chuyển đổi từ ngôn ngữ này sang ngôn ngữ khác, những phần mềm như vậy được gọi là các compiler hay trình biên dịch.
Những trình biên dịch mà đa số chúng ta đều biết như Pascal hay C thực hiện việc chuyển ngôn ngữ bậc cao sang ngôn ngữ bậc thấp là các kí tự 0/1. Đơn giản vì chúng ta dễ đọc ngôn ngữ bậc cao trong khi máy móc thích ngôn ngữ bậc thấp hơn.
Tương tự, Typescript có cấu trúc ngữ pháp chặt chẽ hơn Javascript nhưng nó không được hỗ trợ bởi các trình duyệt. Do đó, các lập trình viên phải tạo ra các công cụ giúp chuyển đổi Typescript code sang Javascript code - transpiler.
Cả hai công cụ trên đều có điểm chung là chuyển đổi code từ dạng này sang dạng khác mà vẫn giữ được logic của lập trình viên.
Hình bên dưới mô tả các thành phần cơ bản của một compiler/transpiler:
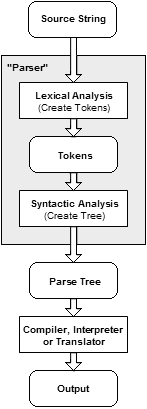
Cấu trúc cơ bản của compiler/transpiler
Để có thể chuyển đổi dễ dàng giữa hai ngôn ngữ, các compiler/transpiler phải biểu diễn được dưới cùng một dạng cấu trúc dữ liệu - chúng được gọi là Abstract Syntax Tree hay AST.
Như bạn có thể thấy, source code sau khi được chuẩn hoá và phân tách từ vựng bởi lexical sẽ được parser chuyển thành cấu trúc ngữ pháp mà có thể biểu diễn được ở cả ngôn ngữ nguồn và ngôn ngữ đích - cấu trúc này gọi là Abstract Syntax Tree. Sau đó, AST được đưa qua translator để chuyển hoá thành ngôn ngữ đích.
Trong compiler/transpiler có nhiều thành phần, nhưng trong phạm vi bài viết này, mình chỉ giới thiệu một thành phần không thể thiếu giúp cho chúng có thể hiểu được ngữ pháp của source code, đó là parser.
Parser là gì?
Parser là một công cụ dùng để chuyển đổi chuỗi các token sang một Abstract Syntax Tree. Có hai loại parser: bottom-up và top-down.
Với bottom-up parser, AST được build up từ dưới lên và ngược lại, top-down parser sẽ build cây từ trên xuống.
Ở đây, mình đưa ra một ví dụ đơn giản để giải thích cũng như demo cho hai dạng parser này như sau:
Có một biểu thức toán học bao gồm các loại phần tử: số, các phép toán cộng (+), trừ (-), nhân (*), chia (/) và hai dấu '(' ')'. Hãy chuyển biểu thức đó thành một AST và chuyển đổi nó sang một chương trình MIPS.
Bottom-up parser
Một biểu thức toán học có nhiều cách biểu diễn và cách phổ biến nhất là dạng trung tố (toán tử nằm giữa hai toán hạng):
1 + 2 * (1 + 3)
Ngoài ra, còn một cách biểu diễn khác là dạng hậu tố (toán tử nằm sau hai toán hạng):
1 2 1 3 + * +
Với dạng hậu tố, chúng ta có thể dễ dàng biến chúng thành một AST với một stack và thuật toán như sau:
-
Đọc token từ danh sách các token.
-
Nếu token là toán hạng, tạo node cho token đó và thêm vào stack và chuyển sang bước 4.
-
Nếu token là toán tử, lấy hai node trong stack, tạo node mới cho toán tử với hai node con trái và con phải lần lượt là hai node vừa lấy ra và đẩy node mới tạo vào stack.
-
Nếu chưa duyệt hết danh sách token, chuyển đến bước 1. Ngược lại, trả về phần tử top của stack.
Vậy làm sao để từ biểu thức trung tố chuyển sang biểu thức hậu tố? Câu trả lời là giải thuật kí pháp Ba Lan được cài đặt với một stack như sau:
-
Đọc token từ danh sách các token.
-
Nếu là toán hạng, đẩy vào danh sách output. Ngược lại, chuyển đến bước 6.
-
Nếu là toán tử, lấy top token cho vào output đến khi nào toán tử đó có độ ưu tiên lớn hơn hoặc gặp dấu '(' và đẩy toán tử đó vào stack. Ngược lại, chuyển đến bước 6.
-
Nếu là dấu '(', đẩy vào stack. Ngược lại, chuyển đến bước 6.
-
Nếu là dấu ')', lấy toàn bộ những phần tử trong stack cho vào output đến khi gặp dấu ngoặc '('. Ngược lại, chuyển đến bước 6.
-
Nếu chưa duyệt hết danh sách token, chuyển đến bước 1. Ngược lại, trả về danh sách output.
Để tối ưu, chúng ta có thể gộp hai bước này và không cần chuyển qua dạng biểu thức hậu tố làm trung gian. Chúng ta sẽ chuyển trực tiếp từ biểu thức trung tố sang AST với 2 stack.
Bạn có thể tham khảo source code của mình ở đây: bottom-up parser

AST của biểu thức: (1 + 1 * 2) / (3 + 5 * 8 - 13)
Top-down parser
Ở phương pháp này, chúng ta sẽ mô tả một biểu thức trên dưới dạng các rules (cú pháp) bằng một meta language, ở đây mình sẽ sử dụng Backus Naur Form hay BNF.
<expression> ::=
<number>
| "(" <expression> ")"
| <expression> <operator> <expression>
<operator> ::= "+" | "-" | "*" | "/"
<number> ::= [1-9] [0-9]*
Điểm mạnh của BNF là nó có thể mô tả các cấu trúc đệ quy một cách dễ dàng và nó cũng là một công cụ ưa thích của các nhà khoa học máy tính khi họ muốn mô tả cú pháp ngôn ngữ của họ. Ví dụ đây là bản mô tả ngôn ngữ C bằng BNF
Bây giờ, chúng ta sẽ chuyển các rule từ BNF sang các hàm của bộ parser một cách dễ dàng như sau:
def number():
global token
expect(TokenType.OPERAND)
next_token()
expect({TokenType.OPERATOR, TokenType.CLOSE_BRACKET})
def operator():
global token
expect(TokenType.OPERATOR)
next_token()
expect({TokenType.OPERAND, TokenType.OPEN_BRACKET})
def expression():
global token
if token.token_type == TokenType.OPERAND:
number()
elif token.token_type == TokenType.OPEN_BRACKET:
next_token()
expression()
expect(TokenType.CLOSE_BRACKET)
next_token()
if is_break():
return
# case: ...<expression> <operator> <expression>
operator()
expression()
Bạn có thể test BNF với BNF Playground
Với cách mô tả như vậy, chúng ta có thể dễ dàng kiểm tra cú pháp của source code, đồng thời tạo ra AST từ source một cách dễ dàng.
Hơn nữa, với cách thực hiện như trên, người ta có thể hoàn toàn sinh ra bộ parser mà không cần viết code bằng tay. Tất cả những gì bạn cần có là một bản mô tả cú pháp cho ngôn ngữ của bạn và đưa qua bộ parser generator là bạn sẽ có source code parser của ngôn ngữ đó.
Các phần mềm như vậy xuất hiện từ khá lâu như GNU Bison hay Yacc.
Với biểu thức ban đầu, mình có thể sinh ra đoạn MIPS code như sau:
mov $0 1
mul $0 2
mov $1 1
add $1 $0
mov $2 5
mul $2 8
mov $3 $2
sub $3 13
mov $4 3
add $4 $3
mov $5 $1
div $5 $4
ret $5
Đoạn code được sinh ở trên còn khá nhiều vấn đề như sử dụng quá nhiều biến không thiết nên trong compiler/transpiler thường sẽ có một bộ optimizer để tối ưu hoá khi sinh source code.
Toàn bộ code mẫu ở trên bạn có thể xem và chạy thử chúng ở đây https://github.com/magiskboy/ast-tut
Ứng dụng của parser
Parser là thành phần không thể thiếu trong các phần mềm compiler như GNU C, Rust, Java,... Nó cũng xuất hiện trong các transpiler như Babel, Typescipt Compiler hay SWC.
Để áp dụng chúng và thực tế, mình có tình huống sau:
Cho đoạn code Typescript bên dưới:
function fib(n: number): number {
if (n < 2) return n;
return fib(n - 2) + fib(n - 1);
}
console.log("foo");
const n = 10;
const ret = fib(n);
console.log(`fib(${n}) = ${ret}`);
Script sau giúp xoá bỏ các lệnh console.log ra khỏi source code ở trên trước khi chúng được transpile sang Javascript:
import ts, { SyntaxKind } from "typescript";
function transformerFactory<T extends ts.Node>(): ts.TransformerFactory<T> {
return (context) => {
const { factory } = context;
const transform: ts.Visitor = (node) => {
if (
node.kind === SyntaxKind.CallExpression &&
(node as ts.CallExpression).expression.getText() === "console.log"
) {
return factory.createVoidExpression(factory.createNumericLiteral("0"));
}
return ts.visitEachChild(node, (node) => transform(node), context);
};
return (node: T) => ts.visitNode(node, transform);
};
}
const result = ts.transpileModule(source, {
compilerOptions: { module: ts.ModuleKind.CommonJS },
transformers: { before: [transformerFactory()] },
});
console.log(result.outputText);
Đoạn code trên sẽ thay thế toàn bộ lời gọi console.log thành void 0 trước khi chuyển chúng sang Javascript
function fib(n: number): number {
if (n < 2) return n;
return fib(n - 2) + fib(n - 1);
}
void 0;
const n = 10;
const ret = fib(n);
void 0;
Ngoài ra, bạn có thể visualize AST của đoạn code Typescript bất kì với TS AST Viewer
Tóm lại, trong bài viết này, mình đã giới thiệu cho bạn về thành phần cũng như cách một compiler/transpiler làm việc cũng như mô tả hai phương pháp để tạo ra bộ parser cho bản thân. Mình hi vọng bài viết này ít nhiều có ích cho bạn và giúp bạn hiểu thêm về quá trình parsing. Bye bye!!